# exam %>% class 1조건 %>% english 열 조회 exam %>% filter(class==1) %>% select(english)
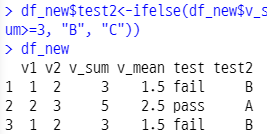
# id, math 열 조회 앞부분 6행 head exam %>% select(id, math) %>% head() # 열추가 함수 mutate 데이터$열이름= exam %>% mutate(total=math+english+science) exam # mutate()를 저장하려면 변수에 담아야 함 # 함수 안쓸거면 원래 하던 거 처럼 이렇게 저장 exam$total = exam$math+exam$english+exam$science # 평균 mean 추가 exam %>% mutate(mean=(math+english+science)/3) # test science 60이상이면 "pass" 아니면 "fail" exam %>% mutate(test=ifelse(science>=60, "pass", "fail"))
< 정렬 : arrange() >
# 정렬 p139 arrange() # math 기준으로 오름차순 exam %>% arrange(math) # math 기분으로 내림차순 desc() exam %>% arrange(desc(math)) # class 오름차순 math 오름차순 arrange(class, math) exam %>% arrange(class, math) # class 오름차순 math 내림차순 exam %>% arrange(class, desc(math))
# 그룹 group_by() summarize() # 전체 수학점수 평균 exam %>% summarise(mean_math=mean(math)) # class별로 math평균 exam %>% group_by(class) %>% summarise(mean_math=mean(math)) # class 별로 math 평균mean(), 합계sum(), 중앙값median(), 개수n() exam %>% group_by(class) %>% summarise(mean_math=mean(math), sum_math=sum(math), median_math=median(math), n_math=n())
# 전체 응용 # 그룹 class, filter class 1반 제외, # mutate 열추가 tot=math+english exam %>% group_by(class) %>% filter(class!=1) %>% mutate(tot=math+english+science) %>% summarise(mean_tot=mean(tot)) %>% arrange(desc(mean_tot))
# 데이터 정제 - 빠진 데이터(결측치), 이상한 데이터(이상치) 제거 p162 # 결측치 찾기 df <- data.frame(sex=c("M","F",NA,"M","F"), score=c(5,4,3,4,NA)) df is.na(df) # 결측치 TRUE table(is.na(df)) # TRUE 2 table(is.na(df$sex)) # TRUE 1 # NA 를 포함하고 있으면 NA 출력 mean(df$score) # NA sum(df$score) # NA # 결측치 제거 # 조건 filter 결측치제거 df %>% filter(is.na(score)) # 결측치 제거 df %>% filter(!is.na(score)) df_nona <- df %>% filter(!is.na(score)) mean(df_nona$score) # 4 sum(df_nona$score) # 16 # df_nona2 score sex NA 없이 저장 df_nona2 <- df %>% filter(!is.na(score)&!is.na(sex)) df_nona2
# 결측치 모두 제거 df_nona3 <- na.omit(df) df_nona3
# NA 그대로 있고 NA 빼고 계산 mean(df$score, na.rm = T) # NA 제외하고 평균 계산 sum(df$score, na.rm = T) # NA 제외하고 합계 계산