1차원 테이블 / 2차원 테이블
2022. 10. 9. 12:36ㆍDev.Program/Python & R
728x90
======== test2.py
# pandas 설치 : R을 보고 만든 파이썬 패키지
# : Numpy 기반으로 만들어짐, 복잡한 데이터 분석
# dataframe 기반 => 엑셀 table, 2차원 배열(리스트) 행, 열에 접근
# 파일 웹, sns, csv(=txt), xml, xls, json, ... 데이터 수집
# 정제 : 이상한 데이터 1 ~ 100 999 -> 처리
# 비어있는 데이터 -> 처리
# 요약 정리 표 -> 시각화(그래프)(->많은 데이터 중에서 원하는 부분만 뽑아서 표를 만듬)

- pandas 설치
< 1차원 테이블 형태 >
| import pandas as pd # Series 1차원 테이블 s1 = pd.Series([10, 20, 30, 40, 50]) print(s1) |

- 인덱스 번호(0~4)도 같이 생성됨! ⇒ 테이블 형태(엑셀형태)의 데이터로 만들어줌
| # index 번호 values 값 print(s1.index) print(s1.values) |

| s2 = pd.Series(['a', 'b', 'c', 1, 2, 3]) print(s2) |

| import numpy as np s3 = pd.Series([np.nan, 10, 30]) # np.nan 비어있는 값 print(s3) |

- 비어있는 값!
| s3 = pd.Series([np.nan, 10, 30]) # np.nan 비어있는 값 print(s3) index_data = ['2020-05-22', '2020-05-23', '2020-05-24'] s4 = pd.Series([100, np.nan, 205], index = index_data) print(s4) |

- 0, 1, 2 인덱스 대신에 설정한 인덱스 값으로 변경 가능
| # 딕셔너리 형태 : 열 이름이 인덱스 이름 s5 = pd.Series({'국어':100, '영어':95, '수학':90}) print(s5) |

| # 날짜 자동 생성 s6 = pd.date_range(start='2019-01-01', end='2019-01-07', periods=None, freq='D') print(s6) s7 = pd.date_range(start='2019-01-01', periods=4, freq='D') print(s7) |


< 2차원 테이블 >
| # DataFrame 2차원 테이블 df1 = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]]) print(df1) |

- 3행 3열로 나옴
| index_date = pd.date_range(start='2020-06-01', periods=3) columns_list = ['A', 'B', 'C'] df1 = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=index_data, columns=columns_list) print(df1) |

| table_data = {'연도':[2015, 2016, 2017], '지사':['한국', '미국', '한국'], '고객수':[200,450,300]} df2 = pd.DataFrame(table_data, index=[1, 2, 3]) print(df2) print(df2.index) print(df2.columns) print(df2.values) print(df2.sum()) # 세로(열)로 더해줌 print(df2.sum(axis=1)) # 가로(행)로 더해줌 print(df2.std()) # 표준편차 print(df2.std(axis=1)) # 표준편차 |

| print(df2.describe()) |

| season_data = {'봄':[256.5, 264.3, 215.9, 223.2, 312.8], '여름':[356.5, 364.3, 315.9, 323.2, 312.8], '가을':[256.5, 264.3, 215.9, 223.2, 312.8], '겨울':[156.5, 164.3, 115.9, 123.2, 112.8]} df3 = pd.DataFrame(season_data, index=[2012, 2013, 2014, 2015, 2016]) print(df3) |
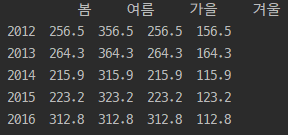
| # 상위 5개 기본 => 3개 print(df3.head(3)) # 하위 5개 기본 => 3개 print(df3.tail(3)) |

| # 1행 ~ 2행 앞까지 추출 print(df3[1:2]) |

- 행이 0부터 시작하기 때문에 2012년이 아닌 2013년부터 시작!
| # 2012 년도 print(df3.loc[2012]) # 2012 ~ 2014 print(df3.loc[2012:2014]) # 봄 print(df3['봄']) |
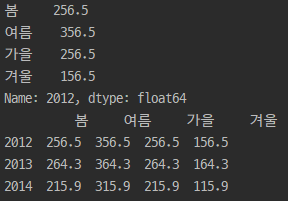

| # 겨울 강수량 120보다 작은 경우 print(df3['겨울']) print(df3['겨울']<=120) print(df3['겨울'][df3['겨울']<=120]) |



| # 행, 열 print(df3.iloc[0,0]) print(df3.iloc[0,1]) # 전치행렬 (역으로 행과 열을 바꿈) print(df3.T) |

| # 열 추가 df3['sum_0']=0 print(df3) |

| # 봄 여름 가을 겨울의 합계 => sum_1 열추가 df3['sum_1'] = df3['봄'] + df3['여름'] + df3['가을'] + df3['겨울'] print(df3) # avg_1 열추가 봄여름가을겨울 평균값 df3['avg_1'] = (df3['봄'] + df3['여름'] + df3['가을'] + df3['겨울'])/4 print(df3) |


| # 열 삭제 df3_1 = df3.drop('sum_0', axis=1) print(df3_1) |

- df3 을 출력하면 sum_0 도 같이 나옴! 따로 df3_1 에 담아서 출력해야함
< 파일 외부로 뽑아내기 >
- 여러 확장자(형식)들 있음!
| df1.to_csv('df1.csv') |
- 실행시키면

> 경로 설정도 가능!
| df1.to_csv('D:\workspace_py\py1\df1_1.csv') |

> 인덱스 이름 설정도 가능!
| df1.index.name = 'date' print(df1) |

< 외부 파일 가져오기 >
- read 적으면 많은 확장자들 보임!
| # 외부파일 -> 데이터 프레임 fdf1 = pd.read_csv('height.csv') print(fdf1) |
- 같은 폴더 내에 있어서 경로지정 따로 줄 필요 없음

| # nation -> index 가져오기 fdf1_2 = pd.read_csv('height.csv', index_col='nation') print(fdf1_2) |

| # math.csv fdf2 = pd.read_csv('math.csv') print(fdf2) fdf2_2 = pd.read_csv('math.csv', index_col='year') print(fdf2_2) |

728x90
'Dev.Program > Python & R' 카테고리의 다른 글
| 여러가지 그래프 (0) | 2022.10.09 |
|---|---|
| 여러가지 메서드 (0) | 2022.10.09 |
| 함수 Import 방법 / 외장함수 (0) | 2022.10.09 |
| 다중 상속 / 함수 / 예외처리 / 파일 읽고 쓰기 (0) | 2022.10.09 |
| 클래스 (0) | 2022.10.09 |