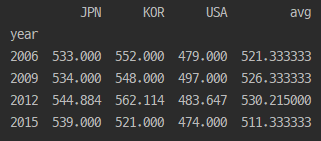
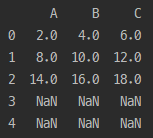
df5=pd.DataFrame({'1반':[95,92,98,100], '2반':[91,93,97,99]}) df6=pd.DataFrame({'1반':[87,89], '2반':[85,90]}) # 1, 2반 5명 <- 전학 2명 추가 print(df5) # 기존 학생 print(df6) # 전학 온 학생 print(df5.append(df6))
합쳤는데 인덱스 번호가 좀 이상함!
# index 번호 새로 부여 print(df5.append(df6, ignore_index=True))
인덱스 번호 새로 부여!
< join() : 열추가 >
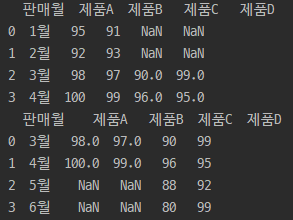
# 3반 추가 => 열추가 df6=pd.DataFrame({'3반':[90,96,88,80]}) print(df5.join(df6))
< sort_values() 정렬 >
# 정렬 : order by -> sort_values() # df9 제품A 오름차순 print(df9.sort_values(by=['제품A'])) # df9 제품A 오름차순 print(df9.sort_values(by=['제품A'], ascending=False))
# 그룹 : group by -> 시각화 # max min sum count mean print(df9.count()) # 제품A 제품B 평균 print(df9[['제품A', '제품B']].mean())
< groupby() : 그룹으로 묶기 >
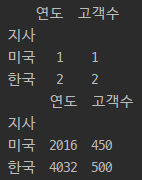
# 지사를 기준으로 그룹으로 묶기 groupby() print(df2) df2_g=df2.groupby(by='지사') print(df2_g)
실행해보면 이렇게 object 로 만들어진 것을 알 수 있다
# 지사별 개수 print(df2.groupby(by='지사').count()) # 지사별 합계 print(df2.groupby(by='지사').sum()) # 지사별 평균 print(df2.groupby(by='지사').mean()) # 지사별 고객수의 최대값, 최소값 print(df2.groupby(by='지사')['고객수'].agg([min,max])) # 지사별 연도 최대값, 고객수 합계 agg_format = {'연도':'max','고객수':'sum'} print(df2.groupby(by='지사').agg(agg_format))
< isna() 비어있는 데이터 찾기 >
# 데이터정제(이상한 데이터, 비어있는 데이터 처리) # 결손데이터 NaN isna() 비어있는 데이터 찾기 df55 = df5.append(df6, ignore_index=True) print(df55) print(df55.isna()) # NaN True print(df55.isna().sum()) # NaN 값의 갯수
NaN이면 True 값 반환
NaN 의 갯수
< fillna() : NaN에 값을 넣는 함수 >
# NaN 결손데이터 다른것으로 대치 => 0, mean() 처리하는데 fillna() <- NaN에 값을 넣는 함수 # '2반' NaN 에 0으로 값 넣어보기 print(df55['2반'].fillna(0)) # '2반' NaN -> 평균 print(df55['2반'].fillna(df55['2반'].mean()))
# lambda 데이터 가공 # 열추가 계산식 -> 람다함수 # 일반함수 하나의 값을 받아서 제곱 리턴하는 함수 get_square() def get_square(a): return a**2 print(get_square(3))
# 람다함수 하나의 값을 받아서 제곱 리턴하는 함수 lam_square() lam_square = lambda a: a**2 print(lam_square(4))
# 결과 리스트변수 = map(람다, 리스트변수) li=[1, 2, 3] result = list(map(lam_square, li)) print(result)
# DataFrame 열 적용 새로운열 = 적용할열.apply(람다함수) 적용할열=>리스트형태 # 새로운 열 추가 df5 '1반100' = 1반열.apply(람다) # 람다 : 하나의 값을 받아서 값*100 리턴 print(df5) df5['1반100'] = df5['1반'].apply(lambda a: a*100) print(df5)
# 1반grade = 1반 람다조건 lambda 받는 변수 : 참값 if 조건 else 거짓값 # 1반 90점 이상이면 'A' 아니면 'B' df5['1반grade'] = df5['1반'].apply(lambda a : 'A' if a>=90 else 'B') print(df5)