기상청 데이터
2022. 10. 9. 12:44ㆍDev.Program/Python & R
728x90
======== test5.py

- 파일 추가하기
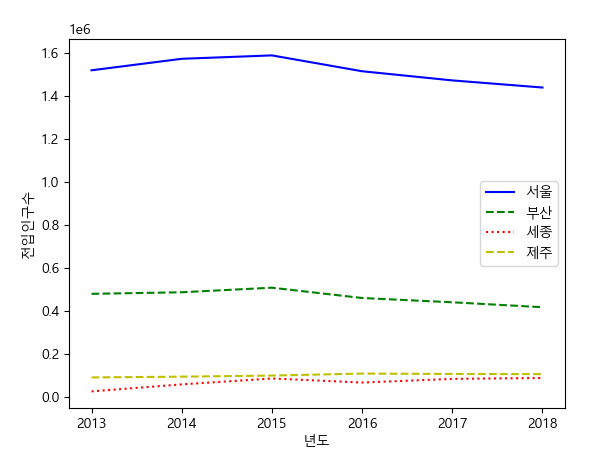
| import pandas as pd import matplotlib.pyplot as plt import numpy as np # 그래프 한글처리 import matplotlib matplotlib.rcParams['font.family']='Malgun Gothic' matplotlib.rcParams['axes.unicode_minus']=False move_p = pd.read_csv('move_P.csv', encoding='cp949') # plt.plot(move_p) index = np.arange(len(move_p)) plt.plot(index, move_p['서울특별시'], 'b-', label='서울') plt.plot(index, move_p['부산광역시'], 'g--', label='부산') plt.plot(index, move_p['세종특별자치시'], 'r:', label='세종') plt.plot(index, move_p['제주특별자치도'], 'y--', label='제주') plt.show() |
| plt.xticks(index, move_p['시점']) plt.legend() plt.xlabel('년도') plt.ylabel('전입인구수') plt.show() |
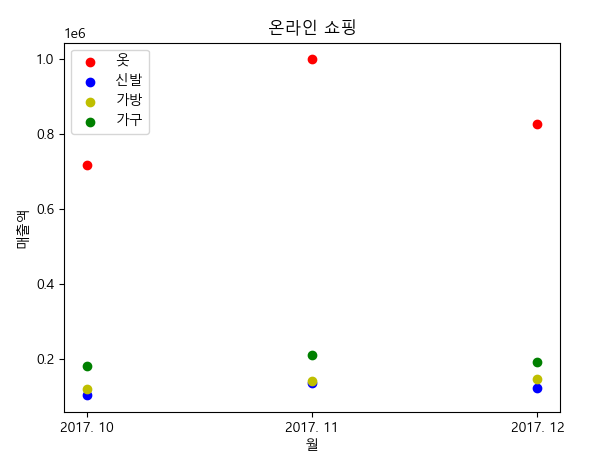
| # 산점도 # online.csv # scatter(x축 '시점',y축 '의 복',color='r',label='옷') # scatter(x축 '시점',y축 '신 발',color='r',label='신발') # scatter(x축 '시점',y축 '가 방',color='r',label='가방') # scatter(x축 '시점',y축 '가 구',color='r',label='가구') # 범례 # 제목 '온라인 쇼핑' # x라벨 '월' # y라벨 '매출액' online=pd.read_csv('online.csv',encoding='cp949') plt.scatter(online['시점'], online['의 복'], c='r', label='옷') plt.scatter(online['시점'], online['신 발'], c='b', label='신발') plt.scatter(online['시점'], online['가 방'], c='y', label='가방') plt.scatter(online['시점'], online['가 구'], c='g', label='가구') plt.legend() plt.title('온라인 쇼핑') plt.xlabel('월') plt.ylabel('매출액') plt.show() |
| # 막대그래프 # birth.csv # ind 구하기 # bar(x축 ind -0.3 , y축'서울특별시', color='salmon', width=0.3, label='서울) # bar(x축 ind , y축'부산광역시', color='orange', width=0.3, label='부산) # bar(x축 ind +0.3 , y축'제주특별자치도, color='skyblue', width=0.3, label='제주) # 제목 '출생아수' # y라벨 'person' # xticks x축 ind => '시점' # 범례 birth = pd.read_csv('birth.csv', encoding='cp949') index = np.arange((len(birth))) plt.bar(index-0.3, birth['서울특별시'], color='salmon', width=0.3, label='서울') plt.bar(index, birth['부산광역시'], color='orange', width=0.3, label='부산') plt.bar(index+0.3, birth['제주특별자치도'], color='skyblue', width=0.3, label='제주') plt.title('출생아수') plt.ylabel('person') # plt.xticks(index,birth['시점']) plt.legend() plt.show() |

======== test6.py
| # test6.py # 데이터 수집 # 웹사이트 수집 : 웹 스크래핑 , 웹 크롤링 html # 웹사이트 -> 주소제공 xml,json,.. # 웹사이트 데이타 -> API # 통계 웹사이트 -> 다운 xml,json,csv,xls,.. # 웹사이트 수집 : 웹 스크래핑 # requests 설치 : 웹페이지 전체 가져오기 # BeautifulSoup4 설치 => 자바 Jsoup : 웹페이지 중에 원하는 부분 뽑아오기 # lxml 설치 |
file - settings - + - requests install

&

beautifulsoup4 설치
&

lxml 설치
| import requests from bs4 import BeautifulSoup # https://www.google.co.kr/ # 사이트 전체 html 가져오기 r = requests.get('https://www.google.co.kr/').text print(r) |
| # 전체 중에 원하는 것을 가져오기 soup = BeautifulSoup(r, 'lxml') print(soup.find('a')) # a태그 찾기 print(soup.find('a').get_text()) # a태그 중에 글자만 찾기 print(soup.find_all('a')) # 리스트로 나옴 |

| li = soup.find_all('a') for i in li: print(i) |
- for 문을 통해 리스트 뽑아올 수 있다!
| # html select() select_one() imgfind = soup.select('body img') print(imgfind) for img in imgfind: print(img) |

- select() 배열 형태로 가져오는 것을 for문을 통해 뽑아냄!
| # https://www.alexa.com/topsites/ # select 순위 사이트 출력 r2 = requests.get('https://www.alexa.com/topsites/').text soup2 = BeautifulSoup(r2, 'lxml') pa = soup2.select('p a') print(pa) for a in pa: print(a) |
- p 태그 안의 a 태그들이 전체 출력됨
| # https://music.naver.com/listen/history/index.nhn r3 = requests.get('https://music.naver.com/listen/history/index.nhn').text soup3 = BeautifulSoup(r3, 'lxml') title = soup3.select('a.title span.ellipsis') for a in title: print(a) for a in title: print(a.get_text()) |
< 기상청 >
# 기상청 전국 날씨 xml 데이터
# http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp?stnId=108

- 기상청 xml 데이터
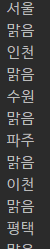
| import os.path import urllib.request as req # 기상청 전국 날씨 xml 데이터 # http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp?stnId=108 # 웹 xml => forecast.xml 파일저장 url = "http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp?stnId=108" if not os.path.exists("forecast.xml"): req.urlretrieve(url, 'forecast.xml') # 파일 열어서 => xml 변수 저장 xmldata = open('forecast.xml', 'r', encoding='utf-8').read() # r = read / read 왕창 readlines 한줄씩 ... # xml 원하는 부분 뽑아내기 BeautifulSoup soup4 = BeautifulSoup(xmldata, 'html.parser') # html 형태로 읽어들이겠다 # 지역 날씨 # find_all() 함수를 많이 씀 # for loc(변수) in find_all('location') # loc.find('city').string # loc.find('wf').string for loc in soup4.find_all('location'): print(loc.find('city').string) print(loc.find('wf').string) |
728x90
'Dev.Program > Python & R' 카테고리의 다른 글
| [R] if문 / 이상치데이터 (0) | 2022.10.09 |
|---|---|
| [R] 데이터 가져오기 (0) | 2022.10.09 |
| 여러가지 그래프 (0) | 2022.10.09 |
| 여러가지 메서드 (0) | 2022.10.09 |
| 1차원 테이블 / 2차원 테이블 (0) | 2022.10.09 |